MMS2R working in Rails 2.3.x and 3.x
I should have been more vocal about this change in MMS2R. Back in February of this year I released MMS2R version 3.0.0 and starting with that version it was dependent upon the Mail gem, rather than TMail. As you might be aware, Mail is the mail gem that ActionMailer is using in Rails 3. Your "legacy" Rails 2.*.* application can still get the benefits of the latest MMS2R versions even though TMail is used by the older ActionMailers.
Here is an example of patching ActionMailer::Base in a way that we can ignore the TMail object it passes to it's #receive method and instantiate a Mail object that we can use with MMS2R.
class MailReceiver < ActionMailer::Base # RAILS 2.*.* ONLY!!! # patch ActionMailer::Base to put a ActionMailer::Base#raw_email # accessor on the created instance class << self alias :old_receive :receive def receive(raw_email) send(:define_method, :raw_email) { raw_email } self.old_receive(raw_email) end end ## # Injest email/MMS here def receive(tmail) # completely ignore the tmail object rails passes in Rails 2.* mail = Mail.new(self.raw_email) mms = MMS2R::Media.new(mail, :logger => Rails.logger) # do something end end
Here is a Gist of the above code where you can fork your own copy, etc. http://gist.github.com/486883.
Not to brag or anything, but I heard twitpic is using MMS2R in part of it's application.
Thank you and enjoy!
Getting Passenger to play nice with Interlock, cache_fu, and Memcached
If you are running your Rails application with Phusion Passenger AND you are caching using Interlock AND/OR cach_fu AND you are using the memcache-client library to connect to your memcache server, then you’ll be seeing plenty of MemCache::MemCacheError errors that might look like these
MemCache::MemCacheError: No connection to server (localhost:11211 DEAD (Timeout::Error: IO timeout), will retry at Mon Dec 10 07:47:23 -0800 2010)or
MemCache::MemCacheError: IO timeoutIf you are using the memcached library to connect to your memcache server then you might be seeing a number of Memcached::ATimeoutOccurred errors that look like this:
Memcached::ATimeoutOccurred: Key {"interlock::controller:action:action:id:tag"=>"localhost:11211:8"}If you are the former with memcache-client errors then don’t believe the examples you’ve seen, memcache-client doesn’t work well with the way Passenger spawns Rails processes. Don’t even try it, use the memcached library instead.
If you are using Interlock and cache_fu in the same application then you need to have the Interlock plugin loaded before cache_fu. Do so in config/environment.rb like so
# load the Interlock plugin first so it will load the memcache client specified
# in memcache.yml otherwise cache_fu will load memcache-client
config.plugins = [ :interlock, :all ]Also, when Passenger spawns a new instance of your application you must reconnect your memcache client from within Passgener’s starting_worker_process event However that code example is vague, here is what it should look like within the Rails::Initializer block in config/environment.rb
Rails::Initializer.run do |config|
# gem and plugin configs above ....
if defined?(PhusionPassenger)
PhusionPassenger.on_event(:starting_worker_process) do |forked|
if forked
# We're in smart spawning mode ...
if defined?(CACHE)
Rails.logger.info('resetting memcache client')
CACHE.reset
Object.send(:remove_const, 'CACHE')
Interlock::Config.run!
end
else
# We're in conservative spawning mode. We don't need to do anything.
end
end
end
endWhat is happening in the code above is that we are closing (with reset) the current memcached connection and are then forcing Interlock to initiate a new memcached connection within it’s helper Interlock::Config.run! method. run! will not fire if the global constant CACHE has already been assigned.
The last thing we need to do is put some timeout protection around the Mecached::Rails client when it is getting and setting values from the memcache server. Interlock has a locking mechanism when its writing to the memcache server and will try to perform the write up to five times if the server doesn’t acknowledge that the write has occured. If a timeout exception bubbles up from the runtime then the purpose of the lock is defeated and it is not able to be retried. The same can be said for reads. Your application shouldn’t have a rendering error if a single read fails to complete from the memcache server. With Interlock if a memached read returns a nil value then all that happends is the code in the behavior_cache and view_cache blocks are executed. Read and write caching errors should not be imposed upon the user’s experience, in my opinion.
To do this make an initializer named config/initializers/memcached_rails.rb as the name reveals the purpose of the file. It will alias method chain Memcached::Rails get and set operations so that they only return nil instead of bubbling up a timeout error when they occur. As I already pointed out if Interlock receives a nil value from a read or a write it will proceed and execute the view_cache and/or behavior_cache blocks you have specified in your application. Memcached::Rails get and set operations underpin Interlock’s reads and writes.
class Memcached::Rails
def get_with_timeout_protection(*args)
begin
get_without_timeout_protection(*args)
rescue Memcached::ATimeoutOccurred => e
if (RAILS_ENV == "production" || RAILS_ENV == "staging")
nil
else
raise e
end
end
end
def set_with_timeout_protection(*args)
begin
set_without_timeout_protection(*args)
rescue Memcached::ATimeoutOccurred => e
if (RAILS_ENV == "production" || RAILS_ENV == "staging")
nil
else
raise e
end
end
end
alias_method_chain :get, :timeout_protection
alias_method_chain :set, :timeout_protection
endIf you are using cache_fu only, you might not have to be so forceful as I’ve been with Interlock to explicitly reset the mecached client. I’m not certain how to explicitly set memcached as the client library in a cache_fu-only environment either, it seems like it has a preference for memcache-client from the its code I’ve reviewed. Post your experiences in the comments for others to learn from if you are in a cache_fu only environment and use these techniques to overcome timeout errors.
will_paginate and PostgreSQL slow count(*)
When a PostgreSQL database table has many rows of data, selecting the count(*) of the rows can be very slow. For instance, a table with over one million rows on an average performing virtual host can take over 5 seconds to complete. This is because PostgreSQL walks through (scans) all the rows in the table. It can be faster if the count(*) includes conditions on table columns that are indexed.
Assuming a Rails application is using the will_paginate plugin to enumerate over the large table, the rendering of each page will take many seconds to complete. This is due to the expense of scanning all the rows in the table as count(*) will be used in the calculation of the will_paginate navigation. Slow Counting is a known and accepted slow performing operation in PostgreSQL
If the Rails application is paginating over all the rows in a table, then a fast approximation technique can be used in place of the count(*) operation. Assuming a Foo model we mark its conditions as ‘1=1’ so that the will_paginate plugin will use our approximation. The pagination would look like the following
Foo.paginate(:page => params[:page], :conditions => "1=1")In a Rails initializer that we call config/initializers/will_paginate_postgresql_count.rb we use a Rails alias method chain to implement our own wp_count method. wp_count is a protected method defined in WillPaginate::Finder::ClassMethods that is used to determine the count of rows in a table, this determines how the will_paginate navigation is rendered. It is selecting the reltuples value from PostgreSQL’s pg_class where relkind equals ‘r’ and relname is the name of the table used by our Foo class. The catalog pg_class catalogs tables and most everything else that has columns or is otherwise similar to a table.. The pg_class approximation will only be used when the conditions given to paginate are ‘1=1’, otherwise the original wp_count method is called. The code is saved in a Gist and listed below below
will_paginate_postgresql_count.rb Gist
# add this file as config/initializers/will_paginate_postgresql_count.rb
# in a Rails application
module WillPaginate
module Finder
module ClassMethods
# add '1=1' to paginate conditions as marker such that the select from the pg_class
# is used to approximate simple rows count, e.g.
# Foo.paginate(:page => params[:page], :conditions => "1=1")
def wp_count_with_postgresql(options, args, finder, &block)
if options[:conditions] == ["1=1"] || options[:conditions] == "1=1"
# counting rows in PostgreSQL is slow so use the pg_class table for
# approximate rows count on simple selects
# http://wiki.postgresql.org/wiki/Slow_Counting
# http://www.varlena.com/GeneralBits/120.php
ActiveRecord::Base.count_by_sql "SELECT (reltuples)::integer FROM pg_class r WHERE relkind = 'r' AND relname = '#{self.table_name}'"
else
wp_count_without_postgresql(options, args, finder, &block)
end
end
alias_method_chain :wp_count, :postgresql
end
end
endPosted in Rails, Ruby, PostgreSQL |
Shoulda macros for rendered partials and globbed routes
Here are a couple of Shoulda macros that I’ve been using. One is to validate that partials are rendered in a view and the other is to validate globbed routes.
should_render_partial
As the name the name implies this macro validates that a partial has been rendered. The macro was born out of the need to test partials being rendered in an implementation of the Presenter Pattern that I wrote. The presenter I wrote was for Appstatz.com a site my friend Shane Vitarana created for tracking iPhone application sales and downloads. The graphs on the site are displayed with the Bluff JavaScript graphing library. The data used by Bluff in each kind of graph was rendered with a composition of different partials. The Presenter Pattern that was implemented was driving which partials were to be rendered based on the state of the application and thus tests were written to validate the implementation of the pattern is acting as expected.
Using should_render_partial takes absolute or relative paths as strings or symbols as its argument and is as easy as this example
class FoosControllerTest < ActionController::TestCase
context "a beautiful Bluff graph" do
setup do
@foo = Factory :foo
get :show, :id => @foo.id
end
should_render_partial 'layouts/_logo'
should_render_partial :_data
should_render_partial :_summary
end
endThe code for should_render_partial is listed below and a Gist of the code is listed at http://gist.github.com/237938
# shoulda validation that a partial has been rendered by a view
class Test::Unit::TestCase
def self.should_render_partial(partial)
should "render partial #{partial.inspect}" do
assert_template :partial => partial.to_s
end
end
endShoulda loads macros from the test/shoulda_macros/ directory therefore add the macro code to a file in that directory.
should_route_glob
Again, as the name implies should_route_glob tests that if there is a globbing route specified in the config/routes.rb then it is acting as expected. Globbed routes should be the last route mapping in the config/routes.rb file as it will greedily respond to all requests. This kind of routing is used in content management systems and I’ve also seen it used in specialized 404 handlers. For instance if an application is ported to Rails, adding a final controller route that accepts all requests would be useful to track down legacy requests. These requests, their URI and parameters, would be stored in a table so they can be inspected later. Using this technique one can easily find legacy routes that are not be handled by the new controllers, or unexpected routes that are exposed from buggy Ajax requests or odd user input, etc.
The routing (implying a controller named Foo) and its functional test are listed below.
ActionController::Routing::Routes.draw do |map|
# GET /a/b/c will be exposed to the action as an array in params[:path] and it
# will have already been delimited by the '/' character in the requested path
map.any '*path', :controller => 'foos', :action => 'index'
endThe test code is as follows.
class FoosControllerTest < ActionController::TestCase
should_route_glob :get, '/a/b/c', :action => 'show', :path => 'a/b/c'.split('/')
endThe code for should_route_glob is listed below and a Gist of the code is listed at http://gist.github.com/237987 This code may be a bit verbose as it appears that (as of 11/18/2009) Shoulda is handling globbed routes better. Add a comment if you improve this should_route_glob macro. Shoulda loads macros from the test/shoulda_macros/ directory therefore add the code to a file in that directory.
class Test::Unit::TestCase
def self.should_route_glob(method, path, options)
unless options[:controller]
options[:controller] = self.name.gsub(/ControllerTest$/, '').tableize
end
options[:controller] = options[:controller].to_s
options[:action] = options[:action].to_s
populated_path = path.dup
options.each do |key, value|
options[key] = value if value.respond_to? :to_param
populated_path.gsub!(key.inspect, value.to_s)
end
should_name = "route #{method.to_s.upcase} #{populated_path} to/from #{options.inspect}"
should should_name do
assert_routing({:method => method, :path => populated_path}, options)
end
end
endMigrating Legacy Typo 4.0.3 to Typo 5.3.X
I completed the process of migrating this blog from Typo 4.0.3 to Typo 5.3.X. These are my notes on the process I undertook to complete the migration. I had self hosted the blog on a Linode slice and part of the migration was to switch the hosting to Dreamhost . I want to retain control of the Rails stack for the blog, but I no longer wanted to maintain the server and base application stack.
Source code
The source for the blog is actually from Frédéric de Villamil’s 5.3.X master Typo branch" at Github git@github.com:fdv/typo and if this isn’t necessary for your blog, you can skip past the git notes and install and maintain the source code in another prescribed manner.
Below are the steps to initialize a new git repository. Add in fdv’s master Typo branch as a remote repository. And finally, merge in fdv’s master branch. You would do so if you planned to frequently pull in the master changes to Typo as its being developed by the community, or if you had another remote branch you wanted to pull in changes from. Remember, at this point we are working locally.
mkdir mynewblog
cd mynewblog
git init
touch README
git add .
git commit -a -m 'start of my typo blog'
git remote add -f fdv git://github.com/fdv/typo.git
git checkout -b fdv/master
git pull fdv master
git checkout master
git merge fdv/masterAlso, you’ll want to install the gems that Typo relies upon, and freeze in Rails 2.3.3
sudo rake gems:install
rake rails:freeze:edge RELEASE=2.3.3
git add vendor/rails
git commit -m 'freezing in Rails 2.3.3' vendor/railsFinally, move the git repository you’ve just initialized to your preferred place to host your projects. Perhaps a private Github repository. I host some of my personal projects on a remote server and just pull from it over ssh.
Migating data
I dumped the production data from my old Typo 4.0.3 blog such that I could migrate it in my local environment.
mysqldump -u root --opt my_old_typo_db > /tmp/old.sqlI then scp’d the old data locally and imported it into a new database that was used for the local migration to Typo 5.3.X.
mysqladmin -u root create typo_development
scp mike@olderserver:/tmp/old.sql /tmp/
mysql -u create typo_development < ~/tmp/old.sql
cp config/database.yml.example config/database.yml
# edit database.yml with local settings
rake db:migrateOne small gotcha for me was that I was using the “recent comments” sidebar from Typo 4.0.3 and I had to manually remove it from the stored settings in the database via the mysql prompt. Use Rails dbconsole script to bring up a mysql console.
ruby script/dbconsoleNow delete the recent comments configuration.
delete from sidebars where type='RecentCommentsSidebar';All of the data should be migrated correctly from 4.0.3 to 5.3.X at this point. Post a comment if you’ve encountered an issue doing your own migration.
Extras
Pink
Pink is punk, and I upgraded the Pink Theme to be Typo 5.3.X compatible. The Pink Theme had been orphaned after 4.0.3 so I had to make some code changes so it would operate in a Typo 5.3.X environment. This is the github project page for Pink http://github.com/monde/pink
I then added Pink as a git submodule so its code would remain independent of my project, yet still be available when the app was deployed.
git submodule add git@github.com:monde/pink.git themes/pink
git submodule updateSee the Capistano notes below for additional information about git submodules and Capistrano
Hoptoad
I’ve had good success with the Hoptoad exception notifier so I added it to my project as well.
ruby script/plugin install git://github.com/thoughtbot/hoptoad_notifier.git
# edit your config/initializers/hoptoad.rb settings
git add vendor/plugins/hoptoad_notifier/ config/initializers/hoptoad.rb
git commit -m 'adding hoptoad notifier and its initializer' vendor/plugins/hoptoad_notifier/ config/initializers/hoptoad.rbI’m not sure if others are deploying plugins as submodules, but I prefer to freeze plugins into my Rails app.
Capistrano
I used the Deploying Rails On Dreamhost with Passenger Rails Tips article and Github’s Deploying with Capistrano article to guide my Capistrano setup. After doing a "capify ." to initialize Capistrano in the project, I added a couple of extra settings and tasks to config/deploy.rb that make the setup specifically tailored for Typo’s configuration on Dreamhost.
First, make Capistrano fetch all the submodules your project is dependent upon during deployment in config/deploy.rb
set :git_enable_submodules, 1The tasks below are also required. The first is the common touch of the tmp/restart.txt file in the current directory that signals Passenger to reload the application. The second task does three things. It links database.yml from the shared directory to the current directory. The second links the shared files directory into the current directory. The public/files directory is where Typo saves any files that are saved as a part of its minimal content management system. Use this strategy so that the files themselves are not dependent upon deployment or stored in your source code repository. Last is something specific to my blog. I use Get Clicky to track visitors statistics. My blog is currently using the Pink theme and I didn’t want to make Pink dependent on my Get Clicky configuration. Therefore I just copy over a modified Pink layout with my Get Clicky settings whenever a new version of the site is deployed.
namespace :deploy do
task :restart do
run "touch #{current_path}/tmp/restart.txt"
end
end
desc "link in shared database.yml, etc. with symbolic links"
task :link_in_shared_files do
run "ln -s #{shared_path}/config/database.yml #{release_path}/config/database.yml"
run "ln -s #{shared_path}/public/files #{release_path}/public/files"
run "cp -f #{shared_path}/themes/pink/layouts/default.html.erb #{release_path}/themes/pink/layouts/"
end
after "deploy:update_code", "link_in_shared_files"Notice that I made the link_in_shared_files task dependent to run after the the Capistrano standard deploy:update_code task has fired.
Redirects
In the virtual host settings for my blog’s old location I promiscuously redirect each request exactly to the new location.
# redirect old apache server:
RedirectMatch permanent ^(.*)$ http://plasti.cx$1These redirects are 301 permanent redirects so that Google and the other search engines will update their indexes permanently to the domain it now resides upon.
Notes
- http://wiki.dreamhost.com/Capistrano
- http://wiki.dreamhost.com/Passenger
- http://wiki.radiantcms.org/How_To_Deploy_on_Dreamhost
- http://railstips.org/2008/12/14/deploying-rails-on-dreamhost-with-passenger
- http://github.com/guides/deploying-with-capistrano
- Get Clicky http://getclicky.com/
- Hop Toad http://hoptoadapp.com/
- Linode http://linode.com/
- Dreamhost http://dreamhost.com/
- Github http://github.com/
The End
So far I’m happy with this setup. For me, its easy to deploy and maintain. Please post any experiences you’ve had with Typo migrations or Typo hosting so that others might benefit from your experience as well.
MMS2R 2.3.0, now with exif, used in Rails apps and Y Combinator startups
I just published a minor point release of the MMS2R Gem version 2.3.0 (http://mms2r.rubyforge.org/). If you were not aware, MMS2R is really just a generic multi-part mail processor. If you have a Ruby application ( Rails, Sinatra, Camping, etc.) and it is processing attachments out of email and/or MMS data, then MMS2R is the gem you should be using. MMS2R has many convenience methods to fetch the most likely image attachment, text attachment, etc. It now gives access to any JPEG or TIFF's exif data using the exifr (http://exifr.rubyforge.org/) reader gem. For instance, MMS2R uses the exif data to detect if the source of the message is from a smartphone like an iPhone or BlackBerry, it could be used for other logic as well.
Back in the summer of 2007 I almost wrote a twitpic.com app using MMS2R, but I couldn't make time for myself to do so. MMS2R would have processed the email extracting images that I had taken with my phone, I would then have posted those to S3 referenced with tiny url links (using Camping Hurl http://github.com/monde/hurl/) into my Twitter feed. I had written MMS2R even earlier than that time, but the emphasis has always been to make it easy to get at MMS data so that it can be used easily in all kinds of applications, social applications in particular.
There are two places to start looking for ideas on how to use MMS2R in a Rails application as I've just described. The first is the PeepCode book Luke Francl (http://justlooking.recursion.org/) and I wrote about it: "Receiving Email With Ruby" http://peepcode.com/products/mms2r-pdf
Another is a recent Rails Magazine article by By Jason Seifer (http://jasonseifer.com/) is titled "Receiving E-Mail With Rails" http://railsmagazine.com/articles/3
There are a number of startups and web sites listed on the MMS2R RubyForge page (http://mms2r.rubyforge.org/) that are using the Gem in their application stack. One of those is Luke's FanChatter (http://www.fanchatter.com/). At the beginning of the summer Fan Chatter received startup funding from Y Combinator (http://ycombinator.com/). So if you use MMS2R in your social Rails application, it might improve your chances of being funded by Y Combinator. Congratulations Luke.
rails coding with vim and autotest
Here is a screen shot of my current environment for programming Rails.
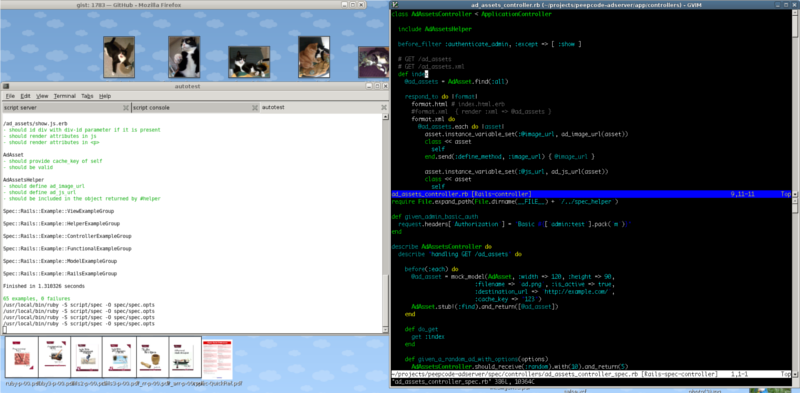
Layout
I’m on Linux and using Gnome as my desktop. On the left hand side is a gnome terminal with autotest running and on the right hand side is gvim. Notice that gvim is split into two horizontal windows the upper is dedicated to the functional code and the lower is dedicated to spec/test code. btw, I’m also using tpope’s rails.vim plugin in gvim as well.
I learned this particular style of having autotest and gvim with functional and testing code all viewable in one location from Eric Hodel Its great, everything is in one place, autotest gives immediate feedback when I’ve broken my code and my functional code and testing code are viewable together.
script it
I wrote a script called railsvim that when called with a rails project directory will open the gnome terminal and gvim in this configuration centered on my desktop. That way I don’t have to place and size all the windows by hand saving me time, e.g.
railsvim ~/projects/superfu
The script is hosted on gist if you like to copy it: railsvim . Looking at a copy of the script below you will find that that gnome terminal is opened with three tabs, one for script/server, one for script/console, and one for autotest which has focus by default since its last tab created.
#!/bin/bash
DIR="${1}"
if [ ! -d "${DIR}" ]; then
echo "call me with a directory, e.g.:"
echo "${0} /some/path/to/dir"
exit 1
fi
gnome-terminal --geometry=130x35+345+250 \
--window --working-directory=${DIR} -t "script server" -e "ruby script/server" \
--tab --working-directory=${DIR} -t "script console" -e "ruby script/console" \
--tab --working-directory=${DIR} -t "autotest" -x autotest &
gvim -c ":wincmd s" -geometry 120x60+1285+0 ${DIR} &
You’ll have to play with the geometry settings for the gnome terminal and gvim to customize the placements for your desktop.
resources
My railsvim script:
Hacking/automating the Linux desktop with wmctrl and others:
tpope (“TextMate may be the latest craze for developing Ruby on Rails applications, but Vim is forever”) rails.vim plugin for powerful vim and rails coding integration
If you have textmate envy here’s how to turn your gvim into a ghetto with their kind of font:
query method pattern, abridged version
Kids that smoke pot grow up to be short adults
Like kids that start smoking pot before the age of 13 stunting their growth, almost every Java programmer has an aspect of their OO programming skills stunted. Namely the OO principle of “Favor ‘object composition’ over ‘class inheritance’.” from the GofF book about design patterns . Because you can’t do that naturally in Java one becomes heavily dependent on class inheritance and your ability to solve problems elegantly in Ruby is extremely disabled when first using the language.
Example
What’s up Java Guy?:
arr = [1, 2, 3,]
if arr.size > 0
#do something
endHow’s it hang’n OO dude?:
arr = [1, 2, 3,]
if !arr.empty?
#do something
# fyi, in ActiveRecord there is arr.any?
endThe Fundamental Idea
Start looking at querying objects for their state instead of pulling their state out of them. When you start doing this you’ll come up on situations where the object is not providing a query method that you need. That is your entry point into the power of Ruby because you’ll start to learn how to open up classes and objects using various Ruby techniques to create the query method needed for the situation.
In the above code there is a comment that ActiveRecord defines #any? for its collections. See the definition of any? in association_collection.rb . Essentially #any? is just !arr.empty? The point being that Ruby didn’t provide an #any? method for collections so it was defined in ActiveRecord. There is no reason that you shouldn’t be doing the same in your code when you need a query method for your situation.
ReihH describes the query method pattern at depth in Ruby Patterns: Query Method and was the inspiration for this post.
Resources
Once you start applying the query pattern in your code you’ll want to follow up by understanding the following posts.
- Ruby Patterns: Query Method http://reinh.com/blog/2008/07/16/ruby-patterns-query-method.html
- Ruby: Underuse of Modules: http://blog.jayfields.com/2008/07/ruby-underuse-of-modules.html
- Class Reopening Hints: http://blog.jayfields.com/2007/01/class-reopening-hints.html
- Seeing Metaclasses Clearly: http://whytheluckystiff.net/articles/seeingMetaclassesClearly.html
MMS2R : Making email useful
Last month before RailsConf Luke Francl and I published "MMS2R : Making email useful" on PeepCode. Its a PDF book so kill all the trees that you can buying it. The book is awesome because of the diversity of experience that Luke brings to the book and Geoffrey Grosenbach is a fabulous editor.
We cover a wide range of experience dealing with MMS in Rails and other applications. An overview is:
- Introduction (protocol, mobile networks, gateways, etc.)
- A Brief History (MMS integrated with web apps, etc.)
- Processing MMS
- Working with ActionMailer (e.g. Rails, daemonizing Rails, IMAP & POP fetching)
- Testing (Test::Unit & RSpec)
- Advanced Topics
MMS2R handles more than just MMS
You may not be aware of this but MMS are just multi-part MIME encoded email. And Luke likes to say that MMS2R is good for email in general not just MMS. MMS2R pulls apart multipart email in an intelligent manner and gives you access to its content in an easy fashion. It writes each part decoded to temporary files and provides a duck typed CGI File so that it is easily integrated with attachment_fu.
Pimp my WWR
I put a lot work into MMS2R so that its easy to access user generated content in an intelligent fashion. Recommend me on Working With Rails if you’ve benefited from this experience and thank you in advance!

Friends of MMS2R
MMS2R and our book would not have been possible without the help of these awesome people from the open source community:
- Dave Myron
- Shane Vitarana
- Will Jessup
- Jason Haruska
- Layton Wedgeworth
- Vijay Yellapragada
- Jesse Dp
- Julian Biard
- Zbigniew Sobiecki
Posted in Books, MMS2R, Nuby Rails, Rails, Ruby |
Ozimodo, Rails based tumblelog, and why its still awesome
One of the coolest small Rails apps is Ozimodo
http://ozimodo.rubyforge.org/ , a Rails based tumblelog
Micro blogging and non-traditional forms of communication are helping to evolve how we’ll be communicating in the future. Its list of contributors is a veritable who’s who in the Rails community.
Here’s an enumeration of aspects that make Ozimodo great in the current context





